


感知
人类天生就配备多种传感器,眼睛可以看到周围的环境,耳朵可以用来听,鼻子可以用来嗅,也有触觉传感器,甚至还有内部传感器,可以测量肌肉的偏转。
通过这些传感器,我们可以感知到我们周围的环境。我们的大脑每分每秒都在进行数据处理,大脑的绝大部分都是用于感知。
无人驾驶车辆也在做这些事情,只不过他们用的不是眼睛而是摄像头。
他们也有雷达和激光雷达,它们可以帮忙测量原始距离,可以得到与周围环境物体的距离。
对于每个无人驾驶汽车,它的核心竞争力之一是利用海量的传感器数据,来模仿人脑理解这个世界。
计算机视觉
作为人类,我们可以自动识别图像中的物体,甚至可以推断这些物体之间的关系。
但是对于计算机而言图像只是红、绿、蓝色值的集合。无人驾驶车有四个感知世界的核心任务:
- 检测——指找出物体在环境中的位置;
- 分类——指明确对象是什么;
- 跟踪——指随时间的推移观察移动物体;
- 语义分割——将图像中的每个像素与语义类别进行匹配如道路、汽车、天空。
图像分类器是一种将图像作为输入,并输出标识该图像的标签的算法,例如交通标志分类器查看停车标志并识别它是停车标志、让路标志、限速标志、其他标志。分类其甚至可以识别行为,比如一个人是在走路还是在跑步。
分类器有很多种,但它们都包含一系列类似的步骤。首先计算机接收类似摄像头等成像设备的输入。然后通过预处理发送每个图像,预处理对每个图像进行了标准化处理,常见的预处理包括调整图像大小、旋转图像、将图像从一个色彩空间转换为另一个色彩空间,比如从全彩到灰度,处理可帮助我们的模型更快地处理和学习图像。接下来,提取特征,特征有助于计算机理解图像,例如将汽车与自行车区分开来的一些特征,汽车通常具有更大的形状并且有四个轮子而不是两个,形状和车轮将是汽车的显著特征。最后这些特征被输入到分类模型中。此步骤使用特征来选择图像类别,例如分类器可以确定图像是否包含汽车、自行车、行人、不包含这样的对象。

为了完成这些视觉任务,需要建立模型,模型是帮助计算机了解图像内容的工具。
摄像头图像
摄像头图像是最常见的计算机视觉数据。

从计算机的角度来看,图像只是一个二维网格被称为矩阵,矩阵中的每个单元格都包含一个值,数字图像全部由像素组成,其中包含非常小的颜色或强度单位,我们可以对其中的数字做出非常多的处理。
通常这些数字网格是许多图像处理技术的基础,多数颜色和形状转换都只是通过对图像进行数学运算以及逐一像素进行更改来完成。
彩色图像被构建为值的三维立方体,每个立方体都有高度、宽度和深度,深度为颜色通道数量。大多数彩色图像以三种颜色组合表示红色、绿色、蓝色,称为RGB图像。对于RGB图像来说,深度值是3,因此可用立方体来表示。
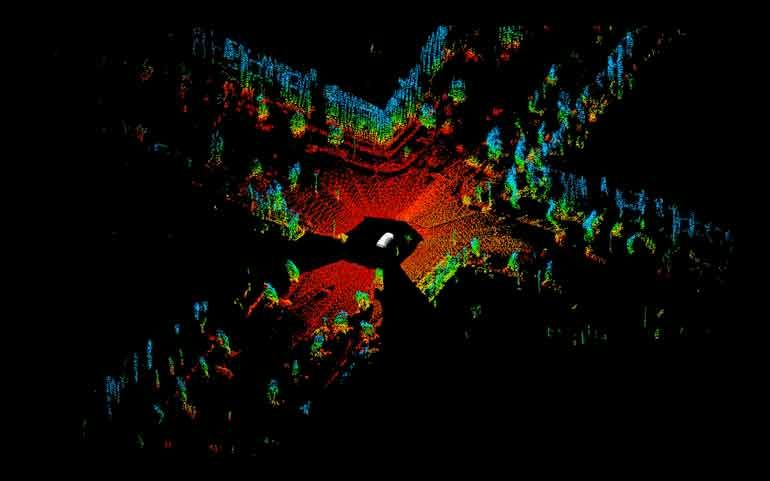
LiDAR图像
激光雷达传感器创建环境的点云表征,提供了难以通过摄像头图像获得的信息如距离和高度。
激光雷达传感器使用光线尤其是激光来测量与环境中反射该光线的物体之间的距离,激光雷达发射激光脉冲并测量物体,将每个激光脉冲反射回传感器所花费的时间。反射需要的时间越长,物体离传感器越远,激光雷达正是通过这种方式来构建世界的视觉表征。
机器学习
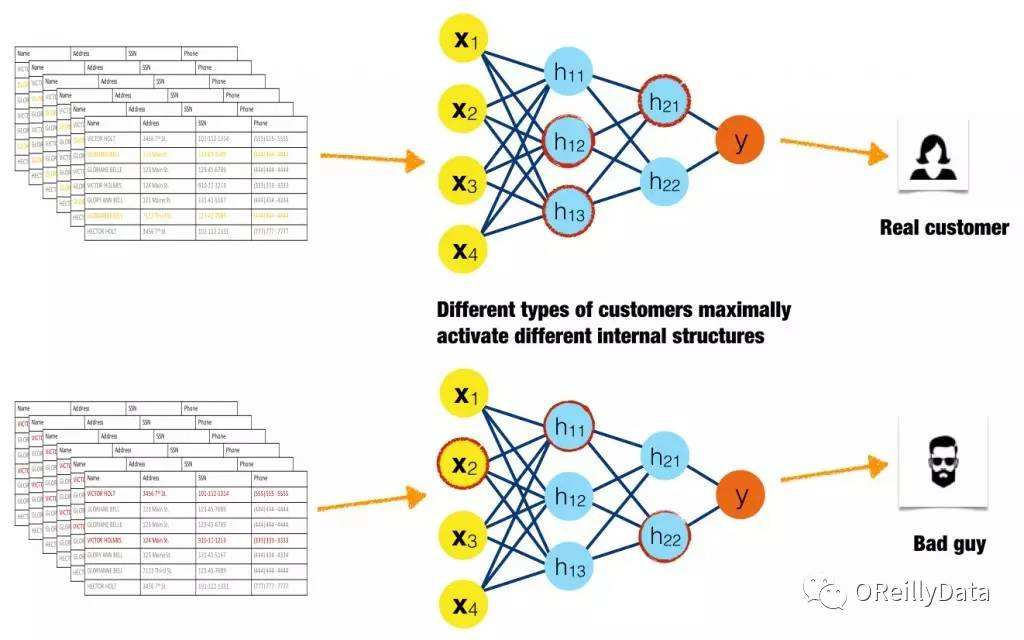
机器学习是使用特殊算法来训练计算机从数据中学习的计算机科学领域。通常,这种学习结果存放在一种被称为“模型”的数据结构中,有很多种模型,事实上“模型”只是一种可用于理解和预测世界的数据结构。机器学习诞生于20世纪60年代,但随着计算机的改进,在过去的20年中才真正的越来越受到欢迎。
机器学习涉及使用数据和相关的真值标记来进行模型训练,例如可能会显示车辆和行人的计算机图像以及告诉计算机哪个是哪个的标签。我们让计算机学习如何最好地区分两类图像,这类机器学习也称为监督式学习,因为模型利用了人类创造的真值标记。







 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)