stata u5笔记
u5notes@用Stata进行量化分析
5.1列联表
列联表
①研究定性变量和定序变量之间关系最好的方法之一是创建列联表。
②大多数研究项目,首先应确定所研究的问题中两个变量的测量尺度。
③定性变量核定序变量一般表示有限多个分类,通常是非数值型的。
④产生多个单个变量的分布要使用tab1而不是tab。
Eg. 研究:不同教育水平的人对冒险的喜欢程度会有所不同:
①为了验证这一假设,可以创建一个表格来并列展示上过大学的年轻人和没上过大学的年轻人对“喜欢冒险”同意程度的分布,这就是要建立的列联表:
②在研究两个变量之间的关系之前最好先研究一下单个变量的分布。
③关于冒险问题的变量被命名为risks,另外还有一个变量cu_attco,用来表示受访者是否上过大学。
④因此将冒险变量转化为二元变量是有意义的,它标明受访者x1是否同意“喜欢冒险“x2的说法。
⑤要创建这个变量,所有属于强烈同意或同意的受访者被归为一个类别,而不确定、不同意和完全不同意的受访者应被归为另一个类别。
⑥应使用带有选项gen(newvar)的recode命令。
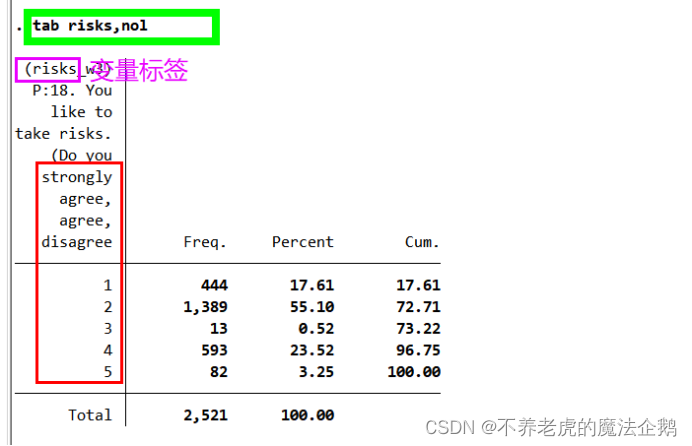
⑦在输入recode命令之前,需要知道变量risks各个类别的数字代码。
在command window输入(→[enter]):
tab risks,nol
⑧通常用0和1代表两个类别。
⑨tab命令:检查一下这个命令是否生成了你想要实现的结果。
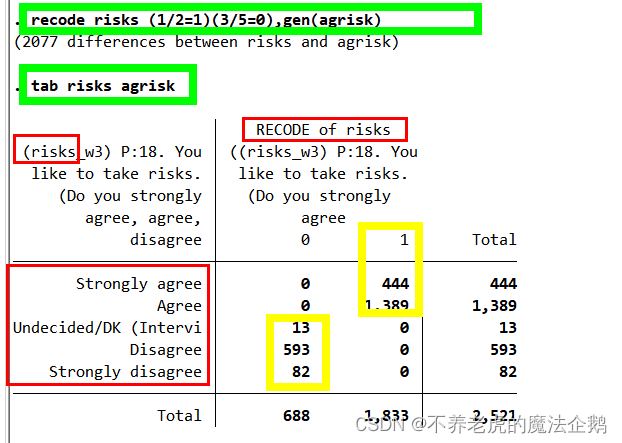
在command window输入(→[enter]):
recode risks (1/2=1)(3/5=0),gen(agrisk)
tab risks agrisk
简单地更改变量的值:
①倒序赋值:数值越大,表示越不同意。
②重新分类:使用带有选项gen(newvar)的recode命令。
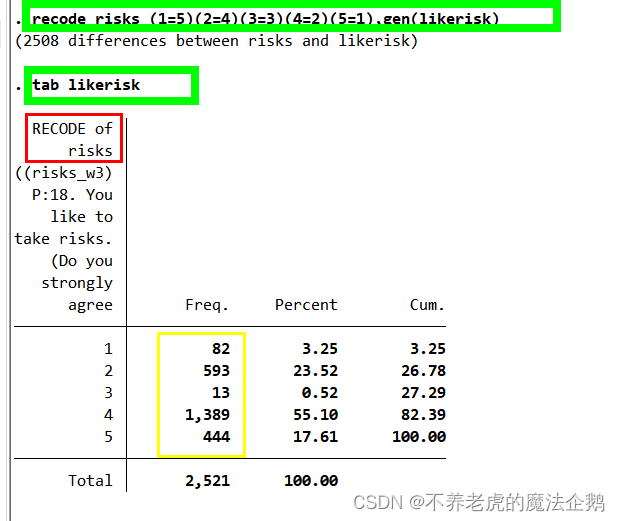
③在新变量中,想让Stata将原变量取值为1的”强烈同意“=5(即最高值)。同理,原来回答”同意“的取值2现在对应4,所有的3(即不确定)可以保持不变,4(不同意)应该取值为2,5(强烈不同意)在新变量中应该取值为最低级的分类1。
④Stata只需要知道旧值和哪个新值相对应即可,下面将产生新变量的分布:
在command window输入(→[enter]):
recode risks (1=5)(2=4)(3=3)(4=2)(5=1),gen(likerisk)
tab likerisk
添加值标签:
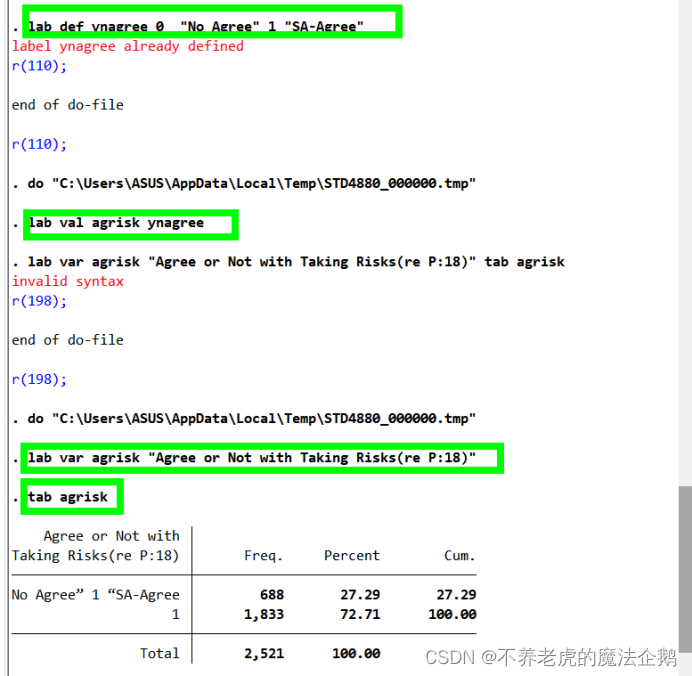
在command window输入(→[enter]):
lab def ynagree 0 "No Agree" 1 "SA-Agree"
lab val agrisk ynagree
①当使用带有选项gen(newvar) 的recode命令时,需要自己生成容易识别的标签(变量标签)。
②这个新标签清楚地解释了变量的含义:这个变量是与问题P:18相对应的回答记录(rc是record的缩写)。→生成一个频数分布:
在command window输入(→[enter]):
lab var agrisk "Agree or Not with Taking Risks(re P:18)"
tab agrisk
生成列联表:
①显示的是冒险变量和是否上大学两个变量之间的列联表。
在command window输入(→[enter]):
tab agrisk cu_attco
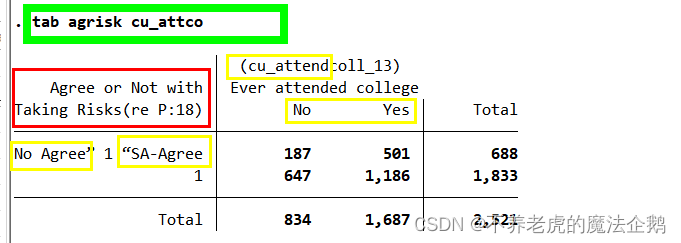
②在tab命令行中输入的第一个变量,被解释变量(结果变量),将在列联表的行中显示。
第二个变量,解释变量(即预测变量or原因变量),则放在列中。
③列联表构建时,对于行变量和列变量,系统没有固定规则。
可以建立自己的规则,如②。
④基于研究目的:
冒险变量:被解释变量,将其放在行中,第一个var。
是否上过大学:解释变量,放在列中,第二个var。
仅仅使用频数分布不能准确评估两个变量之间的关系。
解决:计算百分比:
①根据你相比较的内容来确定这个百分比是基于行还是基于列计算。
②对于这个例子,比较的是:上过大学的人和没上过大学的人对“喜欢冒险”的态度,百分比应设在列。
③在列联表中计算百分比,要求在tab命令后添加选项column(缩写col)或row。
在command window输入(→[enter]):
tab agrisk cu_attco,col
④关于是否同意“喜欢冒险”,上过大学的人和没上过大学的人之间的差异是:7.28%。
⑤如果需要计算行百分比,则可以将选项row添加到上述命令行。
或者更换其中的col选项(如果必要的话,这两个选项可以同时添加,在列联表中显示)。
⑥更简明的表格:可以分别使用nokey和nofreq选项停止显示key和频数。
在command window输入(→[enter]):
tab agrisk cu_attco,col nokey nofreq

⑦这种类型的列联⑥↑可能是实际研究报告的理想选择。但是建议将频数保留。在任何一个研究中,最好先考察最详细的信息,再决定哪些可以去掉。
卡方检验(CHI-SQUARE TEST)
①差异可能是随机发生的,也可能是这组样本中的一些异常所导致的。
②为了进一步检验这种差异是否在年轻人的总体中真实存在,需要进行统计检验,
③在确定两个定性变量或两个定序变量之间是否相关时最常用的检验是卡方检验。
④卡方检验主要检验所观测到的频数是否与两个变量不相关时的频数相同。
两个变量不相关时的频数通常称为“期望频数(expected frequencies)”。
⑤Stata提供了一个直观的选项expected,用来显示每个单元格中的期望频数。
在command window输入(→[enter]):
tab agrisk cu_attco,col expected
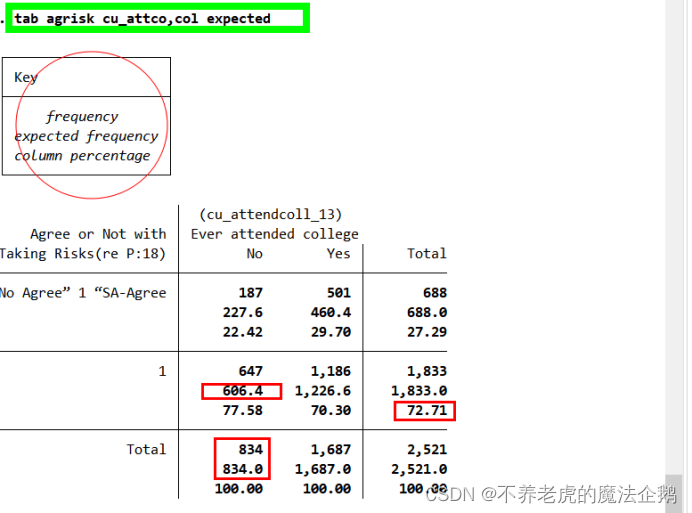
检验是否上过大学对是否同意“喜欢冒险”没有影响:
①如果是否上过大学真的对结果没有影响,那么我们会期望,没上过大学的人和上过大学的人同意“喜欢冒险”的百分比相同,在这个例子中,全样本中有72.71%的人同意“喜欢冒险”,所以如果是否上过大学对是否同意“喜欢冒险”没有影响,那么72.71%就是所有人中同意“喜欢冒险”的百分比。
没上过大学的人同意“喜欢冒险”的预期频数应该为834(所有没上过大学的人)与72.71%(同意“喜欢冒险”人的全样本百分比)的乘积,等于线回收的606.4.
②如果是否上过大学对是否同意“喜欢冒险”有影响,那么实际的频数应偏离这些预期频数。
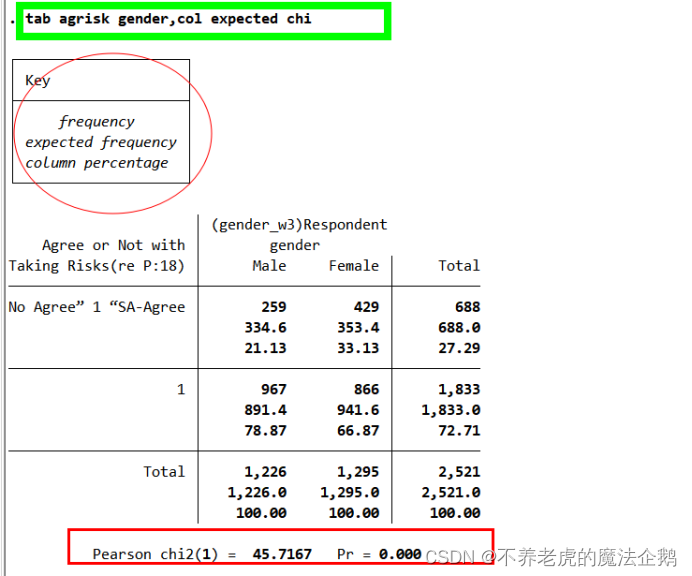
计算卡方统计量:
①选项chi(完整名:chi2)
②其它结果与之前相同,只是表格底部多了卡方检验统计量的值。
③p值是指若果假设关系(即零假设)是真的,那么统计量为当前的概率。
④在卡方检验中,零假设是指两个变量不相关(是否上过大学与是否同意“喜欢冒险”不相关)。
⑤如果原假设不成立,卡方统计量接近于0,这意味着观察到的频数和期望频数没有显著的不同。
⑥本检验给出的卡方统计量比0大很多且p值很小,这表明如果总体中的两个变量之间真的不相关。
⑦p <α=0.05时,原假设不成立。
⑧α=0.05:如果零假设为真,有低于5%的机会得到所观察到的卡方统计量的值。
⑨卡方统计量的值不受变量在行和列的位置影响,如果调换命令行中agrisk和gender的顺序,卡方统计量不变。
在command window输入(→[enter]):
tab agrisk gender,col expected chi
自由度:
不重要。不需要分析。
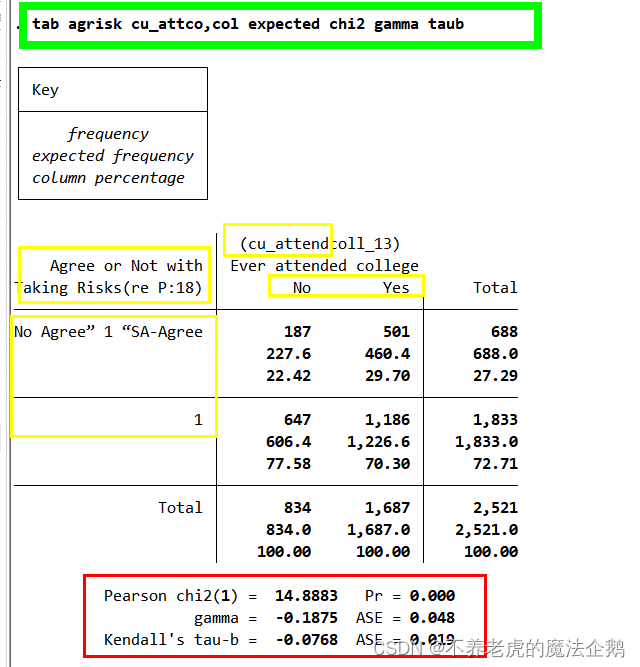
相关性的度量:
①虽然卡方统计量可以很好地说明两个变量是否是显著相关,但没有提供关于相关强度的度量。
②定性变量和定序变量最常用的两种相关性强度是gamma值和Kendall’s Tau-b值。
③gamma值和Kendall’s Tau-b值的选项:gamma和taub
④可以调换命令行中变量的顺序。
⑤变化范围都是从-1到1。绝对值越大意味着相关关系越强,越接近0意味着相关关系越弱。
⑥符号取决于这两个变量时如何取值的。
⑦在这个例子中,gamma值和Kendall’s Tau-b值都是负的。因为上过大学的和同意“喜欢冒险”的编码均为1。因此,负的相关关系说明上过大学的人和同意“喜欢冒险”的人更不同意“喜欢冒险”。
Gamma=-0.1875,和Kendall’s Tau-b,=-0.0768,都表明是否上过大学和是否同意“喜欢冒险”之间不具有很强的相关关系。
在command window输入(→[enter]):
tab agrisk cu_attco,col expected chi2 gamma taub
精细化分析(ELABORATION):分类对比其它因素
①目的:假设提出的因果关系是有缺陷的。
②目的:为了检验性别对相关关系的影响。
③精细化分析:在研究两个变量之间的相关关系时,考虑第三个或其他的影响因素。
④如果对于男性和女性是否上过大学和是否同意“喜欢冒险”之间均具有同样的相关关系,那么性别就不是该相关关系的虚假因素。
⑤需要分别检查male和female两个主变量之间的关系。
⑥用命令bysort:
bysort varname(s):command varname(s) [if varname==value][,options]
bysort将后面的变量自动排序,并且对每个分类执行命令。
Eg.生成不同性别的是否上过大学和是否同意“喜欢冒险”两个变量的列联表:
在command window输入(→[enter]):
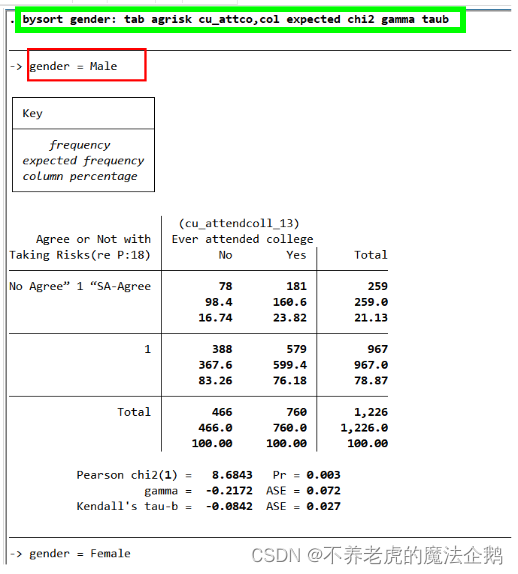
bysort gender: tab agrisk cu_attco,col expected chi2 gamma taub

【注意】
①by命令类似于bysort,但只能指定一个变量进行分类。
by varname(s):command varname(s) [if varname==value][,options]
在command window输入(→[enter]):
②第四章:
在command window输入(→[enter]):
bysort gender:sum bmi
结果表明,对于变量bmi,male的均值比female的均值高。Male至少有一个异常值63.49296可能导致了均值的偏离。
结果:
①female:上过大学的人与没上过大学的人同意“喜欢冒险”的比例之差从7%下降到5%,
同时gamma值和Kendall’s Tau-b值也变小了(接近于0),
卡方统计量的值为0.091,p值不再小于0.05的显著性水平。
不应该拒绝零假设。
②male:上过大学的人与没上过大学的人同意“喜欢冒险”的比例之差相似为7%,
同时gamma值和Kendall’s Tau-b值略有增加,
卡方统计量的值为0.03,p值小于0.05的显著性水平。
应该拒绝零假设。
③在female的样本中是否上过大学与是否同意“喜欢冒险”没关系。
但在male的样本中是否上过大学与是否同意“喜欢冒险”有相关关系。
是否上过大学跟是否同意“喜欢冒险”之间的关系存在于male中。
即上过大学确实会使年轻人倾向于不喜欢冒险,但只是对于male。对于female,是否上过大学与是否同意“喜欢冒险”之间没显著关系。
④这种模式的结果是条件相关的一个例子。
条形多元图
在command window输入(→[enter]):
graph bar (mean) agrisk, over(cu_attco, relabel(1 "No College" 2 "Attend College")) over(gender)


u5notes@用Stata进行量化分析

为开发者提供自动驾驶技术分享交流、实践成长、工具资源等,帮助开发者快速掌握自动驾驶技术。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)