Stata基础绘图教程
这是一份 stata 作图的入门级别教程,附带一些简单的可视化心得。教程内包括了以下图形的绘制及美化:箱图、直方图、柱状图、饼图、折线图、散点图、矩阵图;同时还包括一些基础的 stata 命令逻辑。
目录
引言
这是一份Stata作图的入门级别教程,附带一些简单的可视化心得。
我在工作中学到了不少 Stata 的知识,已经迫不及待想分享给你们啦!当然,我试图把这份教程写得好玩,希望对各位能有所帮助 :)
数据的导入与观察
在 stata 里输入这行命令,你会获得一份 Stata 为你准备好的数据:
sysuse auto, clear //调用Stata的系统数据:auto观察这组数据,你会发现一些变量是分类的(例如 rep78, foreign),另一些变量是连续的(例如price, mpg)。
在进行 stata 绘图时,我们需要考虑两个问题:
- 我们是针对一个变量还是多个变量作图?
- 变量(们)是分类的还是连续的?
我们将一一来看这些情况。
值得一提的是,我建议各位在作图时都采用 #delimit;的分行形式,这一命令表示 stata 只有遇到分号才会换行,其他情况都不会换行。而 #delimit cr 则表示取消这种分行形式。
采用这一分行形式作图的最大优点在于,我们可以将负责不同模块的命令按行分类,同时也便利给每行加上注释,使画图命令更加容易被读者理解。
在下面作图命令的示例中,也将一并演示这一分行方法的应用。
单变量作图
单变量作图被广泛运用在描述统计中。但很多时候必须仔细考量,因为单变量作图有时并不是可视化的好选择,甚至一些情景还不如直接摆上数据直观。
单连续变量作图
1.箱图
现在,我们想了解一下汽车的价格(price)是什么样的。一般而言,箱图(box)是单连续变量作图最广泛的应用。一起动手画一个吧:
graph box price你将收获你的第一个(?)Stata 图形(好耶!),它长这样:

当然,你也可以罗列一些变量,来看看每个变量的分布如何。不过,为了保持可读性,这些变量的分布(第一四分位、中位数等等)不应该差太多。
现在,假如我们想了解汽车里程数(mpg)、行李箱空间(trunk)的分布,并且要稍微美化一下箱型图。
下面的图形会涉及这些知识点:风格设置、线型设置、颜色设置、标记点设置、去网格线、保存。
别担心,我在每行命令后面都加上了注释:
#delimit ;
graph box mpg trunk, //逗号后面表示的是图形的option
scheme(s1mono) //使用s1mono的酷炫黑白风格···(1)
medline(lcolor(black) lwidth(thin)) //把中位数的线变为黑色,线型为 thin
box(1, lcolor(black) fcolor("232 69 69")) //第1个箱,框线黑色,填充的rgb值 ···(2)
box(2, lcolor(black) fcolor("43 46 74 % 70")) //第2个箱,框线黑色,填充的rgb值与透明度
marker(1, msymbol(oh)) //把第 1 个箱型图的离散值点设置为Oh形态 ···(3)
ylabel(, nogrid) //去掉图形的网格线
saving(haoye!!, replace); //把图片保存到本地,命名为haoye!!
#delimit cr
//(1)除此之外,stata还内置有s2mono风格,你还可以外部安装例如tufte, burd等风格模板。
//(2)输入 help colorstyle 以查看全部用法。注意 black%0 和 black*0 是不一样的,前者将是透明的。
//(3)输入 help symbolstyle 以查看全部用法。
// 此外,把 graph box 改为 graph hbox,可以得到横向的箱型图你会获得一张看起来有内味儿了的图片:

输入命令 help graph box 可以查看更多自定义选项。
2.直方图
箱图展示的是比较宏观的分布。但如果我们想了解微观的内容,例如在这份样本中,每个价格区间有多少车呢?显然,箱图无法展示这个结果,这时用直方图(histogram)会清楚很多:
histogram price, freq //price的直方图,纵坐标是频次
默认图形看得真是让人脑阔疼,但别着急,我们有魔法。
接下来有这些知识点:标题设置、直方图起始点、直方图宽度与间距、直方图填充颜色、直方图线条颜色、直方图线条宽度。
#delimit ;
histogram price,
scheme(s1mono) //使用s1mono的酷炫黑白风格
title("hist price") //标题hist price
frequency //也就是freq,你也可以在这里填percent和fraction
start(3000) //第一个柱子从3000开始
width(1000) gap(5) //每个柱子宽1000,柱间距为5
fcolor("155 164 180") //柱填充色rgb
lcolor("120 122 145") //柱外框线rgb
lwidth(medthin); //柱外框线线型medthin
#delimit cr
//直方图的其他知识:
//(1)bin(#)设置有几个柱子;但与width(#)不能共存
//(2)可以输入normal, kdensity加入曲线经过修饰之后的直方图长这样,它可以很好地展示每千元区间内有多少汽车:

输入命令 help histogram 可以查看更多自定义选项。
单分类变量作图
1.饼图
在类别不多的时候,饼图(pie)是个不错的选择。
这里我们还会开始接触作图的条件命令。比如说,我们想了解变量“1978年维修记录”(rep78),同时我们还想排除缺失值(缺失值被记为“.”)尝试输入这个命令:
graph pie if rep78 != ., over(rep78) //over(rep78)表示根据rep78的取值做切片将会得到这样的图形:

请注意,饼图命令基本上都要通过 over 把变量括起来,关于 over 命令我们会在 分类变量 X 连续变量 那一部分更详细介绍。
如果直接写 graph pie rep78,将只能得到一个(发霉的蓝莓蛋糕)漂亮的蓝色圆。

现在,我们例行装饰饼图,我们会开始接触知识点:副标题的设置、图例位置和排布的自定义、添加饼图标签、标签大小设置、更改不同饼块的颜色。
#delimit;
graph pie if rep78 != .,
over(rep78)
scheme(s1mono) //一直用它,怎会如此?
title("pie reg78") //设置标题
subtitle("a nice pie chart", size(*0.7)) //设置副标题,大小为0.7倍
legend(cols(1) ring(0) pos(8)) //图例排成1列,在图中,位置是8点钟方向···(1)
plabel(_all percent, format(%3.0f)) //增加标签,标签保留1位小数
pie(1, color("244 244 242")) //pie1的颜色
pie(2, color("232 232 232")) //pie2的颜色
pie(3, color("187 191 202")) //pie3的颜色,且突出显示
pie(4, color("73 84 100")) //pie4的颜色
pie(5, color("26 55 77")); //pie5的颜色
#delimit cr
//(1)rows(1)则为1行,ring(0)表示图例在图中,pos(#)中#为几点钟的方向Bingo!你会得到一个长这样的饼图:

2.柱状图
饼图固然好用,然而当你面对一个类别很多的变量时,过于细碎的饼图会严重影响食用阅读体验。比如,我们想了解净高度(headroom)的分布。输入 tabulate headroom 会发现它有八个取值:
tabulate headroom
Headroom |
(in.) | Freq. Percent Cum.
------------+-----------------------------------
1.5 | 4 5.41 5.41
2.0 | 13 17.57 22.97
2.5 | 14 18.92 41.89
3.0 | 13 17.57 59.46
3.5 | 15 20.27 79.73
4.0 | 10 13.51 93.24
4.5 | 4 5.41 98.65
5.0 | 1 1.35 100.00
------------+-----------------------------------
Total | 74 100.00
这时,柱状图(bar) 会是一个更好的选择。
上一个命令中,你已经接触到了“over”这一指令,但也许你还不能完全理解它。绘制柱状图能让你对“over”有一个更直观的认识。现在,分别尝试一下这 2 条命令吧:
graph bar headroom //命令1
graph bar, over(headroom) //命令2命令 1 将会得到一个值为 3 的柱子,它的y轴标签是"mean of headroom";

命令 2 才会得到和 tabulate 命令下的表格相关的图表。

发现了吗?命令 1 是描述 headroom 的均值,命令 2 才是依据其取值分组描述。在多变量的章节里,我们还会遇见柱状图,那时你就(一定程度上)会告别“over”指令了。
因此我们学到了一个重要的知识点:over(x) 的含义是,根据变量 x 进行分组绘图。
现在我们在命令 2 的基础上做一些美化,涉及到的知识点包括:y轴刻度的设置、柱体标签的添加、柱体标签保留整数。
#delimit ;
graph bar,
over(headroom)
scheme(s1mono) //老朋友从不缺席,但我保证下个图会换模板
title("bar headroom") //设置标题
bar(1, color("61 131 97") lcolor(black)) //柱体颜色,外框线···Q
blabel(bar, format(%3.0f)) //柱体标签,保留整数
ylabel(0(10)30, nogrid); //y轴标签最小值0,每10作为1刻度,最大值30,去除网格线
#delimit cr
//Q:也许你会好奇,有很多柱状,为什么写1就能更改全部呢?
//A:因为这个数字表示的是“组”换了一个更有活力的颜色,你将获得这样的柱状图:

值得一提的是,我们还需要注意分类的变量是什么样的分类情况。根据不同的分类情况在 x 轴对不同分类进行排序。一般而言:
- 定类变量:由于仅有类别之分,无大小之分,因此按照变量取值的升序/降序排列;例如:按照五个小组参与率从小到大/从大到小排序。
- 定序变量:由于既有类别之分,又有大小之分,因此按照变量本身属性的升序/降序排列。例如:不论频率如何,我们基本习惯于按照受教育程度从小到大排序。
除此之外,如果想绘制横向的柱状图,只需要把 graph bar 更改为 graph hbar 就可以了。
更多关于柱状图的知识请参阅 help bar 命令。
多变量作图
描述统计后的统计推断离不开多变量之间的可视化。
分类变量 X 分类变量
1.交叉表
一般而言,我们很少对双定类变量作图,更经常的情况是使用列联表(交叉表、双向表也是它的名字)去描述它们。例如,我们想看看1978年维修记录(rep78)和汽车来源地(foreign)的交互情况,使用 tabulate 命令:
tabulate rep78 foreign
Repair |
record | Car origin
1978 | Domestic Foreign | Total
-----------+----------------------+----------
1 | 2 0 | 2
2 | 8 0 | 8
3 | 27 3 | 30
4 | 9 9 | 18
5 | 2 9 | 11
-----------+----------------------+----------
Total | 48 21 | 69
说句题外话,对于这种列联表,将它导出至 excel,使用条件格式的数据条/色阶,就能得到一份花花绿绿好读的表格。
分类变量 X 连续变量
1.柱状图:over 与 by
我们要和老朋友见面了:柱状图。
上一章结束的时候,我们提到了柱状图当中“over”的用法,而另一个容易引起混淆的是“by”。
现在设想一下,我们想看看不同汽车来源地(foreign)的汽车价格(price)和汽车重量(weight),分别试试这 3 条命令,看看会画出什么:
graph bar price weight foreign, title("order1") //命令1
graph bar price weight, over(foreign) title("order2") //命令2
graph bar price weight, by(foreign) title("order3") //命令3
将会得到这三张图(我偷偷地组合了一下,后面会有组合图的相关命令),左上的图(order1)表示命令1;右上的图(order2)表示命令2;左下的图(order3)表示命令3:

发现了吗?
不做任何处理的情况下,stata 会绘制出每个变量的均值;
第二,如前面提到,over 表示的是根据……分组,例如 over(foreign) 表示的就是根据变量 foreign 分组。命令中可以出现多个 over ,分组的顺序将会按照 over 的出现顺序,意思即“先根据……分组,再根据……分组”;
而 by 则会对每个分组都做一个图。
当然,你也可以有其他选择,这组数据同样可以用饼图中的 over 和 by 来做可视化。
关于柱状图的美化,因为前面已经提到了,这里不再赘述。
连续变量 X 连续变量
1.散点图
我们想查看不同重量汽车(weight)的售价(price)有何关系。散点图(scatter)跃跃欲试了。
scatter price weight
现在我们熟悉一下散点图的美化,涉及到的知识点包括:如何安装外部包、散点图的点型设置、散点图的点颜色设置、散点图的点大小设置。
//首先,我们抛弃 s1mono,先换个让图形看起来像ggplot的模板
ssc install schemepack, replace //安装 schemepack 模板
//很多外部命令都是使用 ssc install 来安装
#delimit;
scatter price weight,
title("scatter:)") //标题设置为"scatter:)"
scheme(white_tableau)
msymbol(oh) //将点设置为oh形式···(1)
mcolor("33 70 199") //设置点的颜色
msize(medium); //点的大小设置为 medium
#delimit cr
// (1) 输入 help symbolstyle 查看更多点的形式散点图改头换面:

2.散点图与拟合线(图层概念)
尤其需要注意的是,在 stata 里是有图层概念的,后绘制的图层会覆盖先绘制的图层。散点图中,由于经常需要绘制拟合直线和置信区间,因此很容易碰到图层之间的叠加。
现在,假设我们需要绘制上面那个散点图的拟合线和 95% 置信区间。你会在接下来的命令里学习到:stata 绘图中图层的运作形式
分别尝试下面两段命令,它们会产生不同的效果:
第一段命令,先绘制 scatter,再绘制 qfitci(曲线拟合线和置信区间,直线拟合线则为 lfitci):
#delimit;
twoway scatter price weight || qfitci price weight,
scheme(white_tableau)
title("scatter:)") //标题设置为"scatter:)"
msymbol(oh) //将点设置为oh形式···(1)
mcolor("33 70 199") //设置点的颜色
msize(medium); //点的大小设置为 medium
#delimit cr会得到第一个图形:

第二段命令,先绘制 qfitci,再绘制 scatter:
#delimit;
twoway qfitci price weight || scatter price weight,
scheme(white_tableau)
title("scatter:)") //标题设置为"scatter:)"
msymbol(oh) //将点设置为oh形式···(1)
mcolor("33 70 199") //设置点的颜色
msize(medium); //点的大小设置为 medium
#delimit cr会得到第二个图形:

比较两个图形,我们会发现这些不同点:
- 图一中 qfitci 在 scatter 上面,覆盖了一部分点;而图二相反
- 图一中 msymbol, msize, mcolor 三个命令均未生效,如果没有 #delimit;的分行,stata 也许还会报错 msymbol 命令不可用。这是因为 msymbol 只能在 scatter 图形中生效,而不能在 qfitci 图形中生效。
因此,各位在绘制复合图形时,请记得分好图层,避免因为覆盖而损失信息的情形发生。
输入 help scatter 以查看进一步的散点图绘图技巧;输入 help twoway 以查看进一步的多变量绘图技巧。
3.折线图
看到散点图大放光彩之后,折线图也按耐不住了。
折线图(line)表示的是一种趋势,最广泛的运用范围是随时间推进,某一变量的演变过程。
但这份 auto 数据并没有时间序列的变量,为此,我们先自己来创建一个递增的序号。
gen id = _n //生成一个递增的序号,名称是id
sort make //根据make排序,这一步的目的是为了说明后续折线图中的 sort 命令这时假设我们要了解随着序号(id)变动,价格(price)如何波动,绘制折线图会发现:
twoway line price id
之所以出现这样的图形是因为,我们之前输入了 sort make 命令,即按照变量 make 去排序了。
当然,这一步为了模拟真实数据中,变量值的排序不总是规律的,为了让折线图可视化,常态下我们必须在绘图命令里加入 sort。
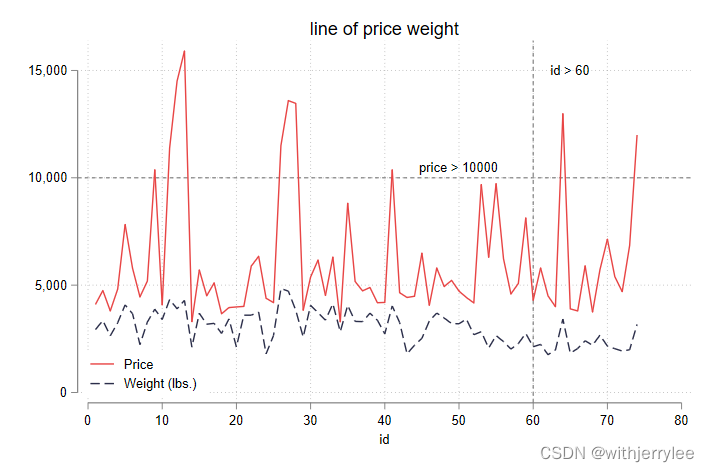
好,来点有挑战性的,假设现在我们要了解随着序号(id)变动,价格(price)和重量(weight)如何波动,并且强调价格 10000 以上和序号在 60 以后的部分。
我们一起来看进阶的折线图绘制命令,涉及的知识点包括:按照特定顺序排序取值、设置 x 轴刻度、设置不同线型、在图表中增加线和文本说明、调整文字大小、调整图例位置。
#delimit;
twoway line price weight id,
title("line of price weight", size(medium)) //标题和字号
sort(id) //根据 id 来排序
scheme(white_tableau) //使用white_tableau模板
xlabel(0(10)80) //将 x 轴刻度设置为 0 开始,每 10 一刻度,最大 80
lcolor("232 69 69" "43 46 74") //两条折线分别的 rgb 值
lpattern(solid dash) // 两条折线的线型,solid 为默认直线,dash 为虚线
yline(10000) // 设置直线 x = 10000
text(10500 50 "price > 10000", size(small)) // 坐标(50,10500)处添加标签,小字号
xline(60) // 设置直线 y = 60
text(15000 65 "id > 60", size(small)) // 坐标(65,15000)处添加标签,小字号
legend(ring(0) pos(7)); //把图例放到图内,位置是 7 点钟方向
#delimit cr锵锵:

连续变量 X 连续变量 X 连续变量
1.矩阵图
有些时候,我们不得不面对观测多个连续变量两两之间的关系,而一一绘制他们的散点图显然是一件很麻烦的事情。不过 Stata 提供了矩阵图(matrix)的绘制。
例如现在我们想了解价格(price)、重量(weight)和长度(length)之间的两两关系,那么我们先绘制基础的矩阵图:
graph matrix price weight length
和散点图一样,我们可以对它进行精修,相信你仍然记得上面散点图的说明:
#delimit ;
graph matrix price weight length,
title("{stSerif:The last graph}", size(medium)) //将标题设置成 Times New Roman ...(1)
scheme(white_tableau) //模板设置
msymbol(th); //将图例设置成空的三角形, h 表示 hallow,没想到吧?
#delimit cr
//(1){stSerif: text} 表示将 “text” 转换为 times new roman,如果实在不喜欢原配字体,可以尝试转换。
图形组合
为了节约空间,我们常常需要把描述同一件事不同方面的图形组合在一块。这个时候,我们就需要使用"graph combine"命令。
比如说,我们现在要组合三个图,图 1 叫做排水量(displacement)和齿轮传动比(gear_ratio)的散点图;图 2 叫做排水量(displacement)在不同来源(foreign)的表现;图 3 叫做齿轮转动比(gear_ratio)在不同来源(foreign)的表现。
综合运用前面所学的知识点,我们开始绘制图形,其中涉及的知识点包括:图形的组合、图形的保存与导出。
#delimit ;
scatter displacement gear_ratio,
title("displacement_gear_scatter", size(medium))
scheme(white_tableau) //设置模板
msymbol(dh) //将点型设置为 dh
saving(displacement_gear_scatter, replace); //保存图 1
graph bar displacement,
title("displacement_foreign_bar", size(medium)) //设置标题,大小为 medium
scheme(white_tableau) //设置模板
over(foreign) //根据 foreign 分组
bar(1, color("52 77 103")) //设置 bar 1 的颜色
blabel(bar, format(%3.2f)) //设置柱体数值标签,保留两位小数
saving(displacement_foreign_bar, replace); //保存图 2
graph bar displacement,
title("gear_foreign_bar", size(medium)) //设置标题,大小为 medium
scheme(white_tableau) //设置模板
over(foreign) //根据 foreign 分组
bar(1, color("52 77 103")) //设置 bar 1 的颜色
blabel(bar, format(%3.2f)) //设置柱体数值标签,保留两位小数
saving(gear_foreign_bar, replace); //保存图 3
graph combine
displacement_gear_scatter.gph displacement_foreign_bar.gph gear_foreign_bar.gph,
scheme(white_tableau)
saving(graph_combine_01, replace);
#delimit cr我们将会得到由三个图形构成的一个图形:

这个图形我们还有一些优化空间,主要是两点:
第一,命令稍显冗长,第二个柱状图和第三个柱状图有大量重复的命令,我们可以使用暂元(macro)进行精简,而这是 stata 绘图中使命令简洁美观的重要方法;
第二,两个柱状图一个在第一行,一个在第二行,不利于读者进行对比,也不符合我们分类的思维方式,因此我们应该考虑调整图片的位置。
我们可以对上面的命令做出这些优化,涉及的知识点包括:暂元在 stata 绘图中的使用、组合图形时对图形的位置更改、图形的导出。
#delimit ;
//设置一个叫做 bar_set_01 的暂元
local bar_set_01
scheme(white_tableau)
over(foreign)
bar(1, color("52 77 103"))
blabel(bar, format(%3.2f));
scatter displacement gear_ratio,
title("displacement_gear_scatter", size(medium))
scheme(white_tableau) //设置模板
msymbol(dh) //将点型设置为 dh
saving(displacement_gear_scatter, replace); //保存图 1
graph bar displacement,
title("displacement_foreign_bar", size(medium)) //设置标题,大小为 medium
`bar_set_01' //调用暂元 bar_set_01
saving(displacement_foreign_bar, replace); //保存图 2
graph bar gear_ratio,
title("gear_foreign_bar", size(medium)) //设置标题,大小为 medium
`bar_set_01' //调用暂元 bar_set_01
saving(gear_foreign_bar, replace); //保存图 3
graph combine
displacement_gear_scatter.gph displacement_foreign_bar.gph gear_foreign_bar.gph,
scheme(white_tableau)
hole(2) //将右上方空出来
saving(graph_combine_02, replace);
//将做好的图形导出至文件夹
graph export
"D:\CSDN Stata\graph_combine_02.png", as(png) name("Graph") replace;
#delimit cr发现了吗,我们先 local 了一个叫做 bar_set_01 的暂元,令这个暂元储存了我们需要输入的柱状图设置参数,此后绘制柱状图时,我们就只需要调用 bar_set_01,在 local 暂元中,调用的形式是使用 `' 把暂元名称括起来。(千万注意两个引号是不同的!)
Stata 还有一种名为 global 的暂元,由于这种暂元使用较少,因此不在这里做更多讲解。大伙要是有兴趣的自行搜索,以及(画饼)如果有机会的话后续我还会出相关教程。
还有一点,在 graph combine 命令的选项里,我们加入了一行 hole(2) 的命令,其作用在于空出右上方的象限。
最终绘制的图形:

那么至此,你已经掌握了 stata 的基本绘图方法,不过教程是死的,大伙还需对实际情况做出分析,绘制最合适的图片进行可视化。祝大家生活愉快 :)
教程索引
最后,为大家汇总了一下我自己绘图学习过程中遇到的好文,感谢这些作者和我的老师们在我学习过程中给予了巨大的帮助:
美观类:
史上最牛Stata绘图模版-schemepack:酷似R中的ggplot2 - 知乎
Stata黑白图形模板:中文期刊风格的纯黑白图形| 连享会主页
基础类:
一文看尽 Stata 绘图_arlionn的博客-CSDN博客_stata画图
用STATA画图—各种作图调整美化命令汇总笔记 - Stata专版 - 经管之家(原人大经济论坛)
进阶类:
Stata:空间计量之用-spmap-绘制地图.md| 连享会主页
天书(基本看不懂但感觉很厉害,希望有缘人能看懂)类:

为开发者提供自动驾驶技术分享交流、实践成长、工具资源等,帮助开发者快速掌握自动驾驶技术。
更多推荐



 55
55 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)